|
・「R with Excel」
・いわゆる「距離」「情報量規準」の類とユーティリティーな関数のなかまたち
(約5000字)
・(いずれも再掲)
https://neorail.jp/forum/uploads/r_metropolitan8_cmp_plot9_ext.png?ref=3896
![https://neorail.jp/forum/uploads/r_metropolitan8_cmp_plot9_ext.png?ref=3896]()
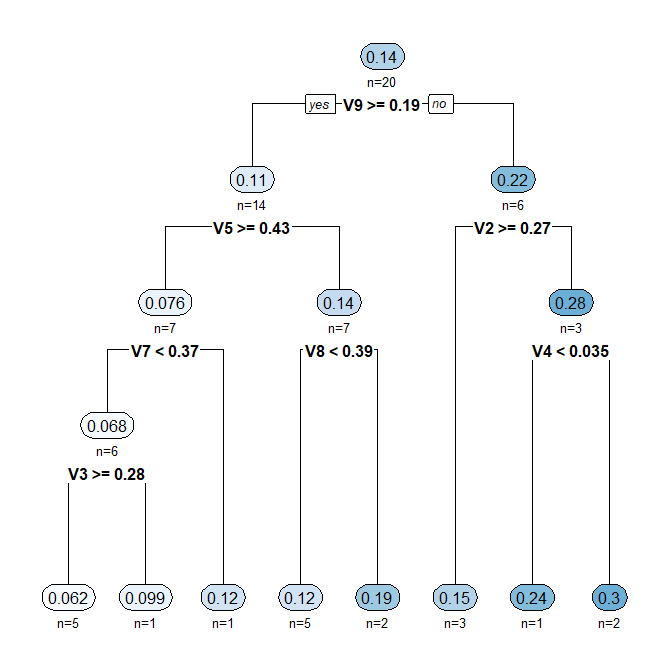
https://neorail.jp/forum/uploads/r_index9_rpart.png?ref=3896
![https://neorail.jp/forum/uploads/r_index9_rpart.png?ref=3896]()
https://neorail.jp/forum/uploads/hclust_zip_t_vec_ward.png?ref=3896
![https://neorail.jp/forum/uploads/hclust_zip_t_vec_ward.png?ref=3896]()
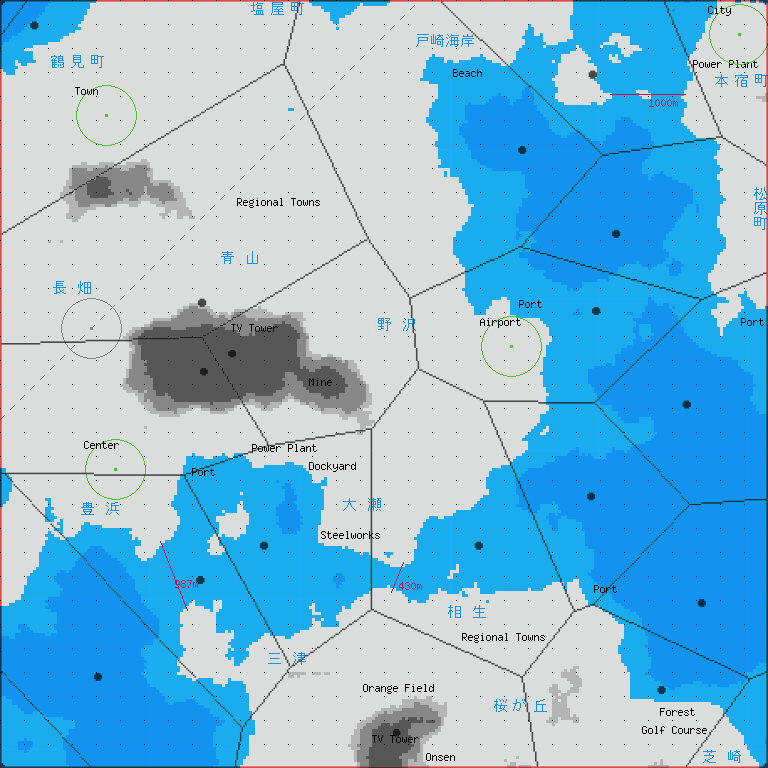
https://neorail.jp/forum/uploads/r_map_region9_voronoi17.png?ref=3896
![https://neorail.jp/forum/uploads/r_map_region9_voronoi17.png?ref=3896]()
いろいろなことをしてたのしくなってきたきょうこのごろ。
・(再掲)日経ビッグデータです(2015年6月24日)
http://business.nikkeibp.co.jp/atclbdt/15/258677/062100001/?P=2
> 私も当初、統計学は積み重ねの学問なので基礎から学ぶべきだと考えていたが、今は考えが変わった。実務で使うのは5つの手法で十分なのに、それらにたどり着く前に統計学の勉強で挫折してしまうのでは意味がない。
「5つ」かどうかは別として、真っ先に本物のデータと本物のツールを実際にじぶんで使ってみなはれということを基本にしようという考えに賛成するものです。それ以外は何も賛成しない。ただし、賛成しないからといって反対しているとは受け取らないでほしい。わるぎはなかった。(キリッ
■「R with Excel」| [3574] | 主成分分析 | prcomp | | [3526] | クラスタリング(クラスター分析) | kmeans・hclust | | [3575] | 回帰木(CART法) | rpart | | [3869] | ボロノイ分割(ディリクレ・テッセレーション) | ggvoronoi |
うーん。
・(再掲)日経リサーチ「固有値分解」
https://www.nikkei-r.co.jp/glossary/id=1605
> 実は、一連の次元縮小法は、ほとんど同じ解析法なのである。それは特異値分解、その特殊な場合の固有値分解である。つまり、
> (1)相関行列の固有値分解 ==> 主成分分析(因子分析)
> (2)頻度行列の特異値分解 ==> コレスポンデンス分析(数量化3類)
> (3)分散比行列の固有値分解 ==> 判別分析
> (4)距離行列の固有値分解 ==> MDS
> というように、入力データが違うだけで、データの解析法は同じである。
工学的に、固有値分解の代わりに特異値分解を使うというのがあるが、同じ考えかただと思ってよい。行列を見たら特異値分解しなはれということである。何も考えずに使えるのが工学的に優れているということである。(キリッ
■いわゆる「距離」「情報量規準」の類とユーティリティーな関数のなかまたち| [3573] | 相関行列 | cor | | [3330] | コサイン距離 | * | | | | | [3526] | 分割表 | ftable | | [3708] | 距離行列 | dist |
*多変量解析にあって、特に何も言わなければユークリッド距離を距離といい、その計算にはコサインを使ってくれるので、距離の計算について説明するならコサイン距離だということ。
・その他の「情報量規準」の類
https://www1.doshisha.ac.jp/~mjin/R/64/64.html
> 情報量
> 情報量規準とモデルの評価
> 情報量規準を用いたモデル評価の例として、三島由紀夫の4作品(遠乗会、卵、詩を書く少年、海と夕焼)の文節の長さの分布のモデルの例を示す。文を文節ごとに切り分け、各文節が何文字により構成されているかを調べたデータを表3に実測値に示す。
> このデータを何らかの確率分布でモデリングすることを考えよう。さまざまなモデルが考えられるが、ここではポアソン分布(M1)と対数正規分布(M2)を用いてモデリングすることにし、
https://www1.doshisha.ac.jp/~mjin/R/68/68.html
> 集計したデータが0、1の二値データや間隔尺度などでる場合は、それに適した類似度、距離の指標を用いるべきである。二値データの類似度としては、一致係数やJaccard係数などがある。
※この説明をまったくせず「Jaccard係数とは」みたいに始まる記事はろくでもないと思へ、の意。
> 階層的クラスタリングは、基本的には距離行列を用いて似ているものを段階的にグルーピングする。階層的クラスタリング法には、単連結法、完全連結法、群平均法、重心法、メディアン法、ウォード法などのアルゴリズムが提案されている。
※「スーパーえむジンせんせい」(※仮名)が体系的かつ網羅的にまとめているし共立出版の赤い本にもなっている。じぶんで書こうとしないで、それを読みましたといって紹介するのが正しい態度である。「スーパーえむジンせんせい」(※仮名)の説明だけではピンと来なかったら「かみつたセンセイ」(※仮名)を読みに行くのである。これで足りないことはおよそない。これだね。
これらは「手法」とは呼ばない。そこの見境がない記事はその程度だ。▼「ティップスせんせい」については[3571]を参照。
・[3571]
> > the proposed algorithms perform significantly better than the standard existing algorithms.
> 比べる相手が素朴すぎるとかって、よくありますよね。…ギクッ。
ソコジャナイ。
> 主成分分析(とも呼ばれる行列の固有値分解[3566])を使わねば何も考察できまいてみたいな状況下から勉強を開始せざるを得ない現代のわたしたち
> つまり、ファジィC-meansなんですね、わかります。
・[3572] 「PLS回帰」を「重回帰分析+主成分分析=主成分回帰(その特別な場合)」に代わって「主成分分析+回帰木」で読み解く(試)
> > PLS回帰は以下の基礎知識に支えられている。
> > PLS回帰
> > 主成分回帰(PCR)
> > 重回帰(MLR) 主成分分析(PCA)
> > よって、この概念図の下から順に取り扱う。
> これ以上に明快な概念図がありましょうか。わたしたち、あたかもSVMやk-meansとも見境なく「分類ができるんでしょ?」といって『決定木』を使うなどの…それでも使えちゃうのもスゴイことではあるんですけど、あっ…といってあしもとをすくわれるやうなとはこのことだよ。
> (単)回帰を重回帰(多変量)に拡張するところ(から※)をきちんと説明することは理想的ではありますが、いくらなんでももどかしすぎるとの感想のほうなど…ゲフンゲフン。この概念図の左半分を下から上まで「回帰木」で代わりとしても、いいと思うんです。ついでに「PLS回帰」より上まで突き抜けて「ツリーモデル」での可視化までできちゃったよ@なんてこったい。
このフォーラム「PLS回帰」の記事([3572])が変にアクセスが多くて(げふ)たいへんしつれいしました。学習の最初の段階でつまづいた人を、しかるべきレールに載せなおす(質問はじぶんの上司に&商用製品を素直に使え!)目的の記事ですので、この記事を読めば「PLS回帰」についてわかるだなんて思わないでください。思わないとは思いますが、念のため。
> いやーテクニカルなんですよ。しかしテクニカルでしかないんですよ。だいたいそういうのが最初から(Rで)パッケージになっていてゲタをはかせてもらっている(≒予算を取れない高校でも使える)、そのゲタは存分に利用しようではありませんか。
https://www.asahi.com/articles/ASN1Z4FC8N1YUCVL025.html
https://yuming.co.jp/discography/album/original26/
https://yuming.co.jp/disco/original/music/26/05.mp3
…GETA! GETA! 走り出す放課後!! AIユーミンなんてしないでよね。(違)
・(再掲)
https://youtu.be/c816jLLf7hc?t=15s
> Gerald Finzi: 5 Bagatelle op.23
> Bibiena Art Festival 2012.
> (映像の13:51)
> ちょっこぼ
> ち・よ・こ・ぼ
> ちょっ・こっ・ぼー
> 少し長めにお聴きください。
…じゃなくて。
> (映像の0:45)
> きょうもげんきだごはんがうまい
> (中略)ぐごー
> (映像の1:07)
> ぱぱー
> (中略)すぴー
> (映像の1:17)
> そして よがあけた!
> (映像の1:23)
> きょうもおべんとうよ。(※「も」に傍点)
> (映像の1:51)
> きょうからはじまる(違)きょうもおしていってくれんかのう(※「も」に傍点)
> わあぃ838861…じゃなくて、15498回。(棒読み)
> (映像の2:54)
> (※効果音「階段」入りまーす)
> てつのきんこがおもい
> おもい
> おもいー
…そっちは連想ですよぅ。GETAだけに。(しーん)
・「GETA」
http://geta.ex.nii.ac.jp/geta.html
> 大規模かつ疎な行列を対象として、
> 行と行あるいは列と列
> の類似度を内積型メジャーで高速計算するツールです。
より一般的な用語(今回の記事で冒頭からここまでに挙げた用語)だけで説明しなおすとどうなりますか&しつれいしました。(棒読み)しかし、いまならコアな計算はRに任せながら、その周辺のプログラムだけ書けば実装できるというかたちで新たなゲタが(げふ)もっとしつれいしました。
> 64bitアーキテクチャ対応
> 複数CPU用
もちろん、「GETA」の本領はそこです。(※恐縮です。)
https://backnumber.dailyportalz.jp/2013/02/27/a/img/pc/000.jpg
・(再掲)譲られた別稿はこちら(※推定)
http://www.kyoritsu-pub.co.jp/bookdetail/9784320111035
https://www.amazon.co.jp/dp/4320111036
> 本書は,重回帰,関数データ解析,樹形モデル,判別分析,一般化線形回帰,ニューラルネットワーク,サポートベクターマシン,生存時間解析について解説し,Rを使ってこれらの手法を利用する方法を述べている。本書で取り上げた手法は,それ自体が有意義なマシンラーニングを実現するための有力な道具であるとともに,より高度な手法を理解したり構築したりする際の礎にもなる。第2版にあたり,第3章 関数データ解析,第7章 ニューラルネットワーク,第9章 生存時間解析を全面改訂した。
・[3571]
> まさにティップスせんせい、第74節から「主成分分析」「クラスター分析」を除いたあたりらへんぜんぶ(ここからここまで)お願いできるかしら(おいくらかしら)みたいな目次になってますよね。
> > (カスタマーレビューより)
> > マシンラーニングと聞いて世間一般の人が想像する「人工知能めいた何かの実装方法」ではなく、「実装方法の基礎理論とRを使ったトレーニング」だと思ってください。
> つまり、ファジィC-meansなんですね、わかります。
> つまり、ファジィC-meansなんですね、わかります。
> > 通常の授業以外に, 校外学習や外部講師による講義
> じぶんでは教えきれないといって、じぶんのせんせいを呼んでくるせんせいって、いますよね。…ギクッ。
ここまで「とにかく「R」を使うには」の話題でした。
|