|
・V1:「「平地」の輪郭のピクセル数」/「「平地」のピクセル数」
・V2:「「-10m」以下のピクセル数」/65536
・V5:「全周(1020ピクセル)における「平地」のピクセル数」/1020
・V6:「全周(1020ピクセル)における「水面」のピクセル数」/1020
・V3:「「山」のピクセルの「高さ」の「中央値」より大きい値の「平均値」/230
・V4:「山の体積」/(256×256×230)
・V7:「「全「水面」の重心」の「マップの中心」からの距離」/(128×√2)
・V8:「「全「山」の重心」の「マップの中心」からの距離」/(128×√2)
・V9:「「全「水面」の重心」と「全「山」の重心」の距離」/(256×√2)
・「R with Excel」
・「R with Excel」(続き)
・「R with Excel」(続き)
・「R with Excel」(続き)
・「R with Excel」(まとめ)
(約19000字)
「事前編」([3881])からの続きです。
・V1:「「平地」の輪郭のピクセル数」/「「平地」のピクセル数」
・V2:「「-10m」以下のピクセル数」/65536
・V3:「「山」のピクセルの「高さ」の「平均値」「中央値」「最頻値」のいずれか大きいの」/230
・V4:「山の体積」/(256×256×230)
・V5:「全周(1020ピクセル)における「平地」のピクセル数」/1020
・V6:「全周(1020ピクセル)における「水面」のピクセル数」/1020
・V7:「「全「水面」の重心」の「マップの中心」からの距離」/(128×√2)
・V8:「「全「山」の重心」の「マップの中心」からの距離」/(128×√2)
・V9:「「全「水面」の重心」と「全「山」の重心」の距離」/(256×√2)
・[3881]
> 次はどのニューゲームを「斬る」のか…ちょっと待ってください。
> マップの画像を人の目で見て目視で視感を述べ(略)人懐っこく感想を述懐し思いをはせて懐かしむ(違)…というのではなく、何らかの変量を用意してクラスタリングしたいものです。何らかの樹形図が描けるといいですね。な・・・なんだってー!!
ここまで頭で考えて言葉だけに頼ってこさえた9つの変量を、実際のデータを使って「R」の上で求めてみましょうではありませんか。
> > 発想としては思いつくけど実装が大変そうでなかなか実行できずにいたけど,
> > 統計ソフトRを用いると本当に気軽にそれが実行出来るということを知った.
「R」を使って、じぶんでは極力、何も書かない(あれやって&これやって、と指示するだけ!)でできるる!!(※音声を変えています。)
・「重心」とは
https://www.pasco.co.jp/recommend/word/word054/
説明の言葉遣いがきもちわるい。
> 点群の重心(Xg、Yg)は以下の式のようにして求められます。
> Xg=(X1+X2+X3+X4+X5)/5 Yg=(Y1+Y2+Y3+Y4+Y5)/5
> 上記のような、仕組みで点群の重心も割り出すことができます。なお、ここでご紹介した方法は、各点の“重み”が同じであることが前提になります。各点に“重み” がある場合については、上記X軸、Y軸にZ軸を足すことで計算ができます。
…あとからいろいろなことを試すかもしれないので生のコードは書かないという方針である。だから「k=1」のk-meansを実行してもいいですか。いいですよね。「重み」が何種類もぶらさがってきても同じ方法でばしつと実行できますよね。本当でしょうか。
・[3868]
> 1度も着ない服(違)
> 自作の関数を定義しています。自作の関数は定義するけれど「for」は使わない。これを対話的という。
これの続きで実行するかもしれないので「myfunc4」から始めませう。
https://www1.doshisha.ac.jp/~mjin/R/Chap_04/04.html
> 統計量にはそのデータの中心の位置を表す代表値として平均、中央値、最頻値が多く用いられている。
「山の高さ」は「10mきざみ!」の整数の値しか持っていないので、あらかじめヒストグラムの階級の設定が済んでいる感じで扱いやすい。こういう値だから最頻値というものが扱いやすい。そうでない場合はあらかじめ「10mきざみ!」とかに自分でするんですよ。そういうことにはなじまないデータなら平均するしかない。本当でしょうか。
> データを大きさの順に並べた場合、中央に位置する値を中央値、あるいはメディアン (median) と呼ぶ。
> (メジアン) を求める関数 median である。
※そこに「最頻値」と誤記されている。なんてこったい。
> R では最頻値を求める関数が用意されていないので、他の関数を用いて間接に求め
最頻値というのは(整数論などというきわめて高尚な議論に立ち入らない場合)算数みたいな話だということです。中央値で済むなら中央値を使えばいい。
> データの数が次のように偶数の場合は、中央の両値を足して2で割った値を中央値とする。
なんかごにょっとした感じではある。
> データが平均値からどの程度散らばっているかを示す量として分散(variance)と標準偏差(standard deviation)と呼ばれている統計量がある。
> データの桁数が多いと扱うのに不便であるので、場合によっては分散値の正の平方根を用いる。分散値の正の平方根を標準偏差(standard deviation)と呼ぶ。
https://www.kotobuki-seating.co.jp/image/school/slide/slide_01.jpg
つまり標準偏差を使えということである。われわれ5人がけの机を鳴らしてイライラしてみせる。前の席の背中に書いてあるコトブキのレタリングをノートに模写してみる。(違)与えるデータの範囲で分散の最大はいくつで、それの正の平方根たる標準偏差の最大はいくつだということを調べておいて、正規化するのか。というか標準偏差って正規化して使ってもいいものなのか? …うーん!! 気がつかなかったことにしよう。(違)
https://www4.kke.co.jp/minitab/support/newsletter/mt200901.html
> データの単位や大きさが異なっていても標準化を実施することで、統計的な取り扱いが便利になります。
> 正規分布は、平均と標準偏差のパラメータから成り立っています。この正規分布を平均0、標準偏差1の、いわゆる標準正規分布に変換することができます。
> もとのデータが正規分布に従っていなくても標準化を利用できます。重回帰分析や多変量解析では、データの単位や大きさが異なっている場合、結果として出てくる係数の扱いを統一するために、分析の前に、データを標準化することがあります。
そういう具体的な処理は「R」の関数にお任せするという態度をとりませう。(※例えば、ここでは主成分分析をするときにprcomp関数を使って、そこでオプションを使っていろいろな処理もしてもらう。)実務にあってはすでにマニュアルがあって、わたしたちは何の試行錯誤も必要なく分析ができる。しかし、ここでは分析結果が正しいの正しくないのということは度外視して(…えーっ)、そこをそうするとそうなるんだね(だからいつもそうしないようにしてたんだね)みたいなことを改めて学んでいければというゆるいコーナーなんですよ。過度な期待はしないでください。
> ちなみにセンター試験の得点分布は、正規分布に近い形になっているそうですよ。
> ちなみにセンター試験の得点分布は、正規分布に近い形になっているそうですよ。
ぬふっ。
https://mathwords.net/hyouzyunka
> 平均は 0、分散は 1 となる。この操作を標準化と言う。
この説明文を暗記させるようではいけない。標準偏差というのはああいうふうにやたら大きな数字になるから、これを0から1の範囲にして見たい。正規化したいというココロがあっての「標準化」という操作である。これを「標準化と正規化の違い」みたいに(この順で)述べたらちゃんちゃらおかしい。
https://kotobank.jp/word/%E3%81%A1%E3%82%83%E3%82%93%E3%81%A1%E3%82%83%E3%82%89%E3%81%8A%E3%81%8B%E3%81%97%E3%81%84-326464
それではまいりませうか。あまりまいりたくなさそうにいってのけてみせるとGOOD!!
・[3733]
> 「列車は224種類あればいいかな」という安易な決定への抜け道(?)をあらかじめ封じられたわたしたち(棒読み)、不安そうに周囲を見渡しながら別の道を探してまいりませうか。…『まいりませうか』!! 水戸のほうから何か飛んでこないかと冷や冷やしながら(違)『重い腰!』をあげませう。
・(再掲)「NMPC-L64」より「region9」のイメージです
https://neorail.jp/fun/NMPC-L64/?map=region9
https://neorail.jp/forum/uploads/map_region9_example.png?ref=3882
![https://neorail.jp/forum/uploads/map_region9_example.png?ref=3882]()
地形をポヤンと見ただけで想像されてきたのはここまで、ということが小さな字でこそこそと書きこんであります。…英語で!(※見解です。)
https://pbs.twimg.com/media/Da06ZVZU8AA-Df7.jpg
「なんでアニメ限定なの?」のフレーズで「なんでオレンジ限定なの?」と不満げに問い返します。どんなオレンジ畑が好き? 畑を耕しに行きましょう。(棒読み)文章を逆順で並べただけで漂う壊れかけのロボット感。なにそれ映画みたい。(違)
・今回のTSVデータはこちらになります
https://neorail.jp/forum/uploads/region9_xyz.tsv
この前([3872])使った「region9」を使いませう。日本国内のプレーヤーで再生できますか。…そのリージョンじゃないやい!(棒読み)
■「R with Excel」| 自作の関数を定義する | # myfunc4
# …と思ったけど、いまはいいや | | | 3軸の座標が入った3列×65536行のテーブル※を読み込む
(タブ区切り) | myakari3d0=read.table("clipboard",h=0) | | 所望のデータ(行)を抽出しておく | myakari3d <- rbind(subset(myakari3d0,V3> 0),subset(myakari3d0,V3< -3))
myakari3dyama <- subset(myakari3d0,V3> 0)
myakari3dumi <- subset(myakari3d0,V3< -3)
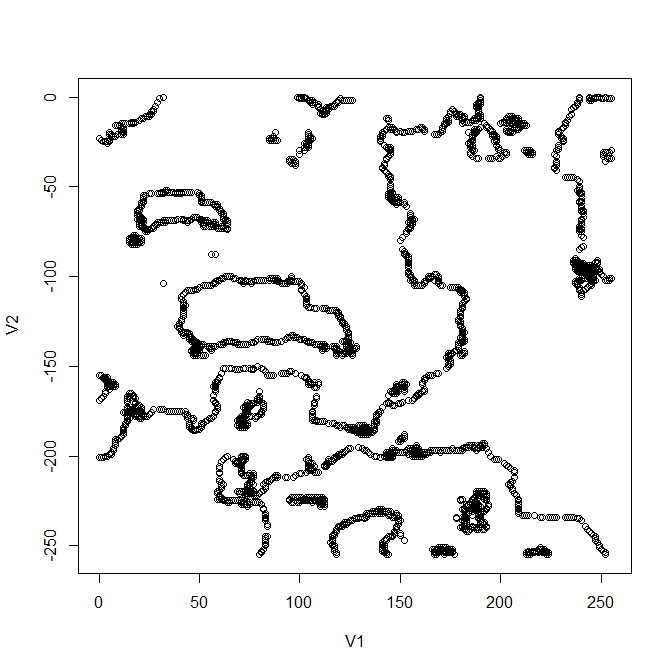
myakari3dedge <- subset(myakari3d0,V3 == -3) | | 点群をプロットして確かめる | plot(myakari3dedge[ , c(1, 2)])
# 3列目(高さ)は使わない | | 抽出される行数だけ知りたい | nrow(rbind(subset(myakari3d0,V3 == 0), subset(myakari3d0,V3 == -3))) | k-meansを実行する
(k=1) | mykmakari3dyama <- kmeans(myakari3dyama, 1)
mykmakari3dumi <- kmeans(myakari3dumi, 1) |
https://pc.watch.impress.co.jp/docs/news/yajiuma/1018662.html
https://pc.watch.impress.co.jp/img/pcw/docs/1018/662/4_s.jpg
> Diamond Multimedia製のビデオカード「EDGE 3D 3240」だ。
そこはかとない「EDGE 3D」のなつかしさよ。(…そこじゃない。)
> > nrow(rbind(subset(myakari3d0,V3 == 0), subset(myakari3d0,V3 == -3)))
「34868」ということです。
https://neorail.jp/forum/uploads/r_region9_3dedge_plot.png
![https://neorail.jp/forum/uploads/r_region9_3dedge_plot.png]()
おおー。(※恐縮です。)しかしそういうふうなデータとしては使わないから行数だけ調べればいい。しつれいしました。
●V1:「「平地」の輪郭のピクセル数」/「「平地」のピクセル数」| nrow(subset(myakari3d0,V3 == -3)) / nrow(rbind(subset(myakari3d0,V3 == 0), subset(myakari3d0,V3 == -3))) |
「region9」では「0.06897442」ということです。
●V2:「「-10m」以下のピクセル数」/65536| nrow(subset(myakari3d0,V3< -3)) / 65536 |
「region9」では「0.4138489」ということです。こちらはほかの変量を求めるときにデータ全体を使うので先に抽出しておきますが、やがては1行で書いて忘れるんでしょうねぇ。(※遠い目)
・「28. 演算子」より「論理演算子」
http://cse.naro.affrc.go.jp/takezawa/r-tips/r/28.html
はまった。すごくはまった。くやしいからかいておく。(違)
https://cfes-project.eco.u-toyama.ac.jp/wp-content/uploads/2017/04/2_objects.html
> さて,特にデータフレームオブジェクトを扱っている場合,「男性のデータ」「日本のデータ」のように,特定の条件を満たすデータのみを抽出したい場合があるだろう.この操作は,デフォルトのsubset()関数でも可能だが,より洗練されたdplyr::filter()関数を用いることを推奨する.
> さて,
> さて,
いまはまだちょっと…(てんてんてん)。
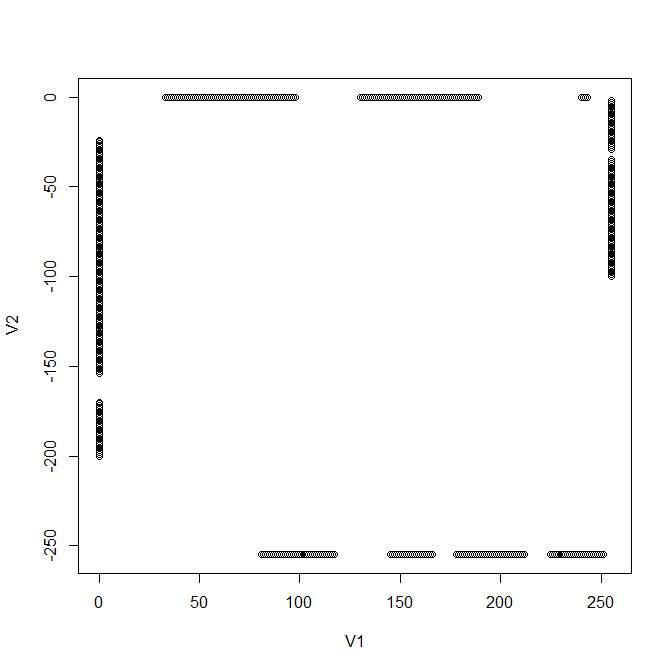
1行で「plot(subset(myakari3d0,( (V3 == 0) & ((V1 == 0) | (V2 == 0) | (V1 == 255) | (V2 == -255)) ))[ , c(1, 2)])」みたいなことをして確かめてみる。
https://neorail.jp/forum/uploads/r_region9_0-0-255-255_plot.png
![https://neorail.jp/forum/uploads/r_region9_0-0-255-255_plot.png]()
やりたいことができているからよし。
●V5:「全周(1020ピクセル)における「平地」のピクセル数」/1020| # 演算子を半角で表示すると表組みが崩れるというローカルな事情で、下の行に書いてあります |
「nrow(subset(myakari3d0,( (V3 == 0) & ((V1 == 0) | (V2 == 0) | (V1 == 255) | (V2 == -255)) ))) / 1020」するのである。「region9」では「0.4970588」ということです。
●V6:「全周(1020ピクセル)における「水面」のピクセル数」/1020
「nrow(subset(myakari3d0,( (V3 < -3) & ((V1 == 0) | (V2 == 0) | (V1 == 255) | (V2 == -255)) ))) / 1020」するのである。「region9」では「0.4294118」ということです。それはつまり、「1-(0.4970588+0.4294118)」が「山」なんですが…(てんてんてん)。「nrow(subset(myakari3d0,( (V3> 0) & ((V1 == 0) | (V2 == 0) | (V1 == 255) | (V2 == -255)) ))) / 1020」で確かめると「0.04019608」です。1から引いて求めようという時でも生の値でなくそこに関数を書くべき。(キリッ
「重心」を見ていきませうか。
> > mykmakari3dyama$centers
> V1 V2 V3
> 1 85.31782 -135.535 62.85674
でぃーやま!!
> > mykmakari3dyumi$centers
> エラー: オブジェクト 'mykmakari3dyumi' がありません
でぃーうみ!!
> > mykmakari3dumi$centers
> V1 V2 V3
> 1 156.4669 -143.1592 -57.58683
…げふ!! こんなのは一瞬だから変数名(データフレーム名)を考えて与えるのすらめんどい。必要な時に何度でも「kmeans(myakari3dyama, 1)$centers」みたいに呼んでもいいじゃないか。結果も変わらないからだいじょうぶだ。本当でしょうか。この前の「dist()」の無駄づかいよりははるかにマシである。それは確かに本当らしい。
・V3:「「山」のピクセルの「高さ」の「平均値」「中央値」「最頻値」のいずれか大きいの」/230
| median(as.matrix(subset(myakari3d0, V3> 0, c(3)))) / 230 |
うーん。いまさらふつーに中央値とか最頻値とか…いえ、順番が逆になったとは思うけれど「いまさら」などといわず、中央値とか最頻値みたいな簡単なやつだからエクセルでできるよとか言わないで、Rの上で完結させませう。
まず「median(as.matrix(subset(myakari3d0, V3> 0, c(3))))」は「50」と出てきます。「230」のほうは、そのマップでは出てこないかもしれない値なので「230」と与えてやらないといけません。そのようにして「region9」では「0.2173913」ということです。
いよいよ最頻値です。
http://webbeginner.hatenablog.com/entry/2014/07/03/173000
> names(which.max(table(oridata)))
…なーんだ。(※恐縮です。)
■「R with Excel」(続き)| 平均値を求める | mean(as.matrix(subset(myakari3d0, V3> 0, c(3))))
# subset関数はベクトルを返すのでas.matrixしておく | | 中央値を求める | median(as.matrix(subset(myakari3d0, V3> 0, c(3))))
# subset関数はベクトルを返すのでas.matrixしておく | 最頻値を調べる
(画面で見るだけ) | table(subset(myakari3d0, V3> 0, c(3)))
plot(table(subset(myakari3d0, V3> 0, c(3))))
# ふむふむ | | 最頻値を求める | as.integer(names(which.max(table(subset(myakari3d0, V3> 0, c(3)))))) | | 標準偏差を求める | sd(as.matrix(subset(myakari3d0, V3> 0, c(3))))
# subset関数はベクトルを返すのでas.matrixしておく |
平均値は「62.85674」ということです。標準偏差は「43.78355」ということです。
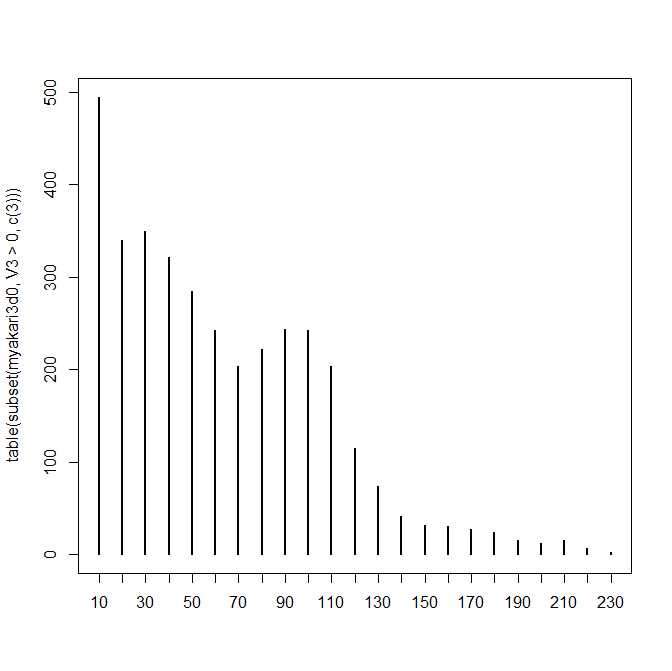
https://neorail.jp/forum/uploads/r_region9_elv_hist.png
![https://neorail.jp/forum/uploads/r_region9_elv_hist.png]()
> > table(subset(myakari3d0, V3> 0, c(3)))
>
> 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230
> 495 340 350 321 285 243 204 222 244 243 204 115 74 41 32 31 27 24 15 12 15 7 2
それを行列とみなして最大値を持つ行を見つけて行名を調べるんですね。そうすると文字列型になってるから「as.integer」しておくんですね。「region9」では「10」ということです。いくら「対話的」とはいえ、そこに表示されたのを人の目で読み取って「10だね」とかぶつぶついいながら紙に書き写すわけじゃないんで「as.integer」しないといけない。ここテストに出ます! …出ません!!(※見解です。)
■「R with Excel」(続き)平均値、中央値、最頻値を求め
その最大値を求める | myakari230mean <- mean(as.matrix(subset(myakari3d0, V3> 0, c(3)))) / 230
myakari230median <- median(as.matrix(subset(myakari3d0, V3> 0, c(3)))) / 230
myakari230mode <- as.integer(names(which.max(table(subset(myakari3d0, V3> 0, c(3)))))) / 230
max(rbind(myakari230mean, myakari230median, myakari230mode)) | | 標準偏差を使って標準化する | ( median(as.matrix(subset(myakari3d0, V3> 0, c(3)))) - mean(as.matrix(subset(myakari3d0, V3> 0, c(3)))) ) / sd(as.matrix(subset(myakari3d0, V3> 0, c(3))))
( as.integer(names(which.max(table(subset(myakari3d0, V3> 0, c(3)))))) - mean(as.matrix(subset(myakari3d0, V3> 0, c(3)))) ) / sd(as.matrix(subset(myakari3d0, V3> 0, c(3)))) |
| | 230で
割った値 | この分布における
平均値と標準偏差を使って
標準化した値 | ←を10倍して50を足す | ←100で割る | | | | | | | | (とりうる最大値) | 230 | 1 | 3.81749 | 88.1749 | 0.882 | | | | | | | | 平均値 | 62.85674 | 0.2732902 | 0 | 50 | 0.500 | | 中央値 | 50 | 0.2173913 | -0.2936432 | 47.06357 | 0.471 | | 最頻値 | 10 | 0.04347826 | -1.207228 | 37.92772 | 0.379 | | | | | | | | (とりうる最小値) | 10 | 0.04347826 | -1.207228 | 37.92772 | 0.379 |
※ここではsubset関数の返り値が空でない=「山」とみなされる点群があるという前提ですが、「山」とみなされる点が1つもなければ「0」です。そういう特殊な場合のみ「0」という値をとり、少しでも「山」があれば、ぜんぜん「0じゃない」値をとる。あしからず。
「0.2732902」が選ばれてきます。これは平均値を230で割った値です。ところで、比べるのが2つだけならIF文の要領で条件式で大小を比べたりしちゃいそうなところではありませんか。最初にそういう発想をしてしまうと比べるのが3つや4つに増えるとどうしたらいいのかわからなくなるし、そういうことだから3つや4つに増やすこと自体をいやがるようになる。それは困る。だから最初から、もし2つしかなくてもrbindしてmax関数で調べる。実になんでもないことではあるけれど、実はすごく大事なことなんですよ。じぶんでじぶんに言い訳をさせないよう先手を打っておく、ちょっとテクニックでした。(棒読み)
https://www.shop.jal.co.jp/contents/shop/jalux/img/goods/94921/94921_94921.jpg
そして、地形データの表現上、256×256のすべての地点で高さが「230m」という、四角い容器の上まですりきりのゼリーみたいなこともできなくはないので、あくまで高さの平均値などを「230」で割るというプリミティヴな操作がいちばん表現したいことを表現する方法だといえます。ここでは標準化という操作は必要ない。本当でしょうか。(棒読み)
・「エクセルでいうところのいわゆるTRIMMEAN関数」とはにわ
https://dekiru.net/article/4521/
https://oku.edu.mie-u.ac.jp/~okumura/stat/basics.html
> 運動競技などの採点で,極端な点数を付ける審査員の影響を少なくするために,点数を大きさの順に並べて,両側から同数ずつ削除してから平均を求めることがあります。このような平均を,トリム平均(トリムド平均),調整平均,刈り込み平均(trimmed mean)などと呼びます。Rでは mean() に trim=... というオプションを与えて計算します。
> > mean(x, trim=0.2)
あるんですねぇ。
> これら三つの代表値の使い分けとしては,データの分布が後で説明する正規分布に近いなら平均値,後で説明するコーシー分布のように極端な値が非常に多いならメジアンのほうが安定した結果が得られます。トリム平均は,分布にかかわらず,最善ではないけれども妥当な代表値となるものとして,近年よく使われています。
ここでは「山」の高さのインパクトのようなものを知りたいので、どれでもいいから大きいの(=高さが高いの)をとろうと、こういうわけです。だからといって、[3881]で最初に素朴に挙げた「最高地点の高さ」みたいな1点をそのままとるのでは、ほとんどのマップで同じとか、そもそも高さの値は「10mきざみ!」でしか変わらないから階段状にしか見えないとか(げふ)もう少しマップごとの違いが反映されてほしい。どうしたらいいですか。(棒読み)
・[3881]
> V3というのは、遠景として山を眺めたときに目に入る「これが山ですよ」という(スクリーンに投影した平べったい平面の「山の絵」における)図形の重心のようなものということですか。このあたりの「山」は「だいたいこんな高さ」と認識する、山頂の1点ではなく山体全体の存在感のようなものを見よう(≒それがどのくらいの仰角になるか)ということですか。
じゃあ(※)「中央値」より上半分(上位50%)の平均とかできないの。…ギクッ。
●V3:「「山」のピクセルの「高さ」の「中央値」より大きい値の「平均値」/230中央値より大きい値を抽出し
その平均値を求める | mean(as.matrix(subset(myakari3d0, V3> median(as.matrix(subset(myakari3d0, V3> 0, c(3)))), c(3)))) / 230 |
じぶんで並べ替えて個数を調べてその半分の個数を上から順にとるというような生の操作は書かない。それはぜんぶmedian関数に任せる。なあに、subset関数なんて軽いものさ。何度でも呼んでいい。(棒読み)そして「230」で割る前の値は「98.88889」で、割ると「0.4299517」ということです。(ばーん
このとき「中央値は何番目か」「それより上をとる」という操作にはなっておらず、「中央値より大きい」というトリムをするので、この「region9」でいえば「50m」という点はぜんぶ見なくなって「60m」以上の点だけをとる、必ず「50%」より少ない範囲を見ることになるわけですが、…むしろいい。(キリッ
https://www.kajima.co.jp/tech/c_projects/ex/2016ktnhgh/images/img_04.jpg
https://www.kajima.co.jp/tech/c_projects/ex/2016ktnhgh/images/img_01.jpg
・[3881]
> …なぜに東花園だし。
近景の(特に高層というわけでないふつうの高さの=31mまでの)建物などで遮られて「山」の低いところは見えない、それでも建物の背後の「山」が見えれば存在感があるし、そのときどのくらい視界を占めますか、みたいなことである。31mまでの高さの建物の半分くらいの高さの階(ビルの4階くらい=頭1つは出た高さではある)から眺めるとして「山」に目をやり青葉(げふ)きょうもいいてんき(しばらくお待ちください)ニューゲーム(がふっ)そういう「目の高さ」で自然に見て「山」がちょうどよいのがいいんですよ。あまり迫りすぎてもいけないしほとんど見えない(「山」の形がわからない)のもおもしろくない。(※恐縮です。)
https://kobun.weblio.jp/content/%E3%82%81%E3%81%AB%E3%81%AF%E3%81%82%E3%82%92%E3%81%B0
> 前書きに、「かまくらにて」とある。鰹(かつお)は鎌倉の名物であった。
> 自評に「目には青葉といひて、耳にほととぎす、口に鰹、とおのづから聞こゆるにや」とあるように、「目には」に対応する「耳には」「口には」を省略した句法が新鮮だった。
…きょーしゅくです!(違)
●V4:「山の体積」/(256×256×230)| sum(as.matrix(subset(myakari3d0, V3> 0, c(3)))) / (256 * 256 * 230) |
うーん。まず「222890」という『体積!』が得られ、これを「15073280」という銀座千疋屋の四角いゼリーみたいなので割る格好です。そうすると「0.01478709」だということです。こういうのが1行ですぱっとできるのが「R」なんですよ!(どやぁ
●V7:「「全「水面」の重心」の「マップの中心」からの距離」/(128×√2)| 高さを無視する場合 | dist(rbind(mykmakari3dumi$centers[ ,c(1,2)], c(127.5, -127.5)))[1 ] / (127.5 * sqrt(2)) | | 高さも使う場合 | dist(rbind(mykmakari3dumi$centers, c(127.5, -127.5, 0)))[1 ] / (127.5 * sqrt(2)) |
うみー! 「region9」では、高さを無視する場合は「32.92856」、高さも使う場合は「66.33652」ということです。『128×√2』すなわち「127.5 * sqrt(2)」は「180.3122」です。これで割ると、それぞれ「0.1826197」「0.367898」になるということです。
うっかり「128」などと(げふ)座標は0から255まで整数しか取らないので、中心は「127.5, -127.5」(※プロットの都合でy座標はマイナスにしています)という、データ点としてはとりえない点だということです。
dist関数の返り値は行列になっています。たまたま要素数が1個なので何も言わなくてもなんとなくできちゃうけれど、ちゃんと1番目の要素を1個だけ取り出しますよという「[1 ]」をつけておかないとあとで型がおかしいといわれますよ。な・・・なんだってー!!
※「[1 ]」というのは、このフォーラムの仕様のせい(=その記法ではフォーラムの記事を参照してしまう=)で余計なスペースを追加せざるを得ない、の意。スペースを含んだままでもRで正しく実行できます。
●V8:「「全「山」の重心」の「マップの中心」からの距離」/(128×√2)| 高さを無視する場合 | dist(rbind(mykmakari3dyama$centers[ ,c(1,2)], c(127.5, -127.5)))[1 ] / (127.5 * sqrt(2)) | | 高さも使う場合 | dist(rbind(mykmakari3dyama$centers, c(127.5, -127.5, 0)))[1 ] / (127.5 * sqrt(2)) |
やまー!
「region9」では、高さを無視する場合は「42.94062」、高さも使う場合は「76.12402」ということです。『128×√2』すなわち「127.5 * sqrt(2)」は「180.3122」です。これで割ると、それぞれ「0.2381459」「0.4221789」になるということです。
●V9:「「全「水面」の重心」と「全「山」の重心」の距離」/(256×√2)| 高さを無視する場合 | dist(rbind(mykmakari3dumi$centers[ ,c(1,2)], mykmakari3dyama$centers[ ,c(1,2)]))[1 ] / (255 * sqrt(2)) | | 高さも使う場合 | dist(rbind(mykmakari3dumi$centers, mykmakari3dyama$centers))[1 ] / (255 * sqrt(2)) |
うーん。「71.5564」「140.0963」になって、割ると「0.1984236」「0.3884825」です。
・[3881]
> V7とV8とV9が見ているのは直接には「水面」と「山」の重心ではあるけれど、その値が大きいほど、マップの中心から「空」が見えるということである。
> V9は、それだけを見れば『風光明媚度の逆数!』(※超訳)である。山と水面が近接していれば「絵になる」風景に違いない。
V7、V8、V9のいずれも、「高さ」は無視するのがよいでしょう。本当でしょうか。たぶん本当です。(棒読み)そらー! 本件ゲームで「空」というのは「2000m」くらいまで考える感じなので、そのスケールにおいて「山」が「230m」だの「海」が「-80m」だのというのは平べったくつぶれて見えていいんだということにしませう。これはじぶんで決めることです。うん。(※あくまでゲームです。)
ところで、マップに「水面」がありませんとか「山」がありませんというとき、V7、V8、V9は無限大というかそういう感じの値になってほしい。「水面」がないときは「水面の重心」が「-255,255」(※マップ左上の外側)に、「山」がないときは「山の重心」が「511,-511」(※同右下の外側)にあることにする、そうすれば重心があるときに求まってくるどんな値よりも大きくできる。本当でしょうか。
■「R with Excel」(続き)点群がないとき
指定の値を重心とする | myakari3dyama <- subset(myakari3d0,V3> 0)
myakari3dumi <- subset(myakari3d0,V3< -3)
mykmakari3dyamacenter <- kmeans(myakari3dyama, 1)$centers
mykmakari3dumicenter <- kmeans(myakari3dumi, 1)$centers
# 点群がないときはエラー
if (nrow(myakari3dyama)< 2) { mykmakari3dyamacenter <- data.frame(V1=c(511), V2=c(-511), V3=c(0)) }
if (nrow(myakari3dumi)< 2) { mykmakari3dumicenter <- data.frame(V1=c(-255), V2=c(255), V3=c(0)) } |
エラーになったからといって止まったりしないで、その関数は実行できませんでしたよというだけで淡々と進んでいくのが「R」なんですね。ふつうのプログラミング言語とは勝手が違う。
subset関数が「0行」の結果を返し、「0行」の「mykmakari3dyama」などつくってくれる。nrow関数で行数を調べれば「0行」といわれる。「mykmakari3dyama」などが「0行」のときに、重心をじぶんで「511,-511,0」などにしておけばいいんですよ。このため、k-meansの結果もちゃんと覚えさせておくことにする。しかしcentersしか使わないのでそこだけ覚えることとする。(キリッ
…などと考えて、そういうコードのまま実はちょっと集計してしまったんですけれど、幸いにもそこまでの集計ではこれが効いてくる場面はなかった。これでは0から1にしたいのに2という値が出てしまう。V7やV8の値そのものを1にするコードを書いておけばいいだけだった。めったなことでは1になどならないから、1という値でじゅうぶん、意味的には無限大である。しつれいしました。
そして、1点しかないのに実行したkmeans関数は重心が「0」だとかいう。なるほどnrowで行を調べるときは「2行未満」という条件式にするんですな。しつれいしました。kmeans関数を自分勝手に使うので、すべて責任は自分にかかってきます。0行のときと1行のときのことを考えるというケッタイな責任がね。(※恐縮です。)
■「R with Excel」(まとめ)…そうそう、あなたは
そこでそうやってコピペ
していればいいのよ
考えることなんて
なにもないのよ
コメント行すらも
そのまま実行したって
害はないのよ
ところでさっきからずっと
じゅげむさんがお呼びよ? | myakari3d0=read.table("clipboard",h=0)
# データをクリップボードにコピーしてからEnter
# あるいはファイルで用意しておく
myakari3d <- rbind(subset(myakari3d0,V3> 0),subset(myakari3d0,V3< -3))
myakari3dyama <- subset(myakari3d0,V3> 0)
myakari3dumi <- subset(myakari3d0,V3< -3)
myakari3dedge <- subset(myakari3d0,V3 == -3)
mykmakari3dyamacenter <- kmeans(myakari3dyama, 1)$centers
mykmakari3dumicenter <- kmeans(myakari3dumi, 1)$centers
# 点群がないときはエラー
v1 <- nrow(subset(myakari3d0,V3 == -3)) / nrow(rbind(subset(myakari3d0,V3 == 0), subset(myakari3d0,V3 == -3)))
v2 <- nrow(subset(myakari3d0,V3< -3)) / 65536
v3 <- mean(as.matrix(subset(myakari3d0, V3> median(as.matrix(subset(myakari3d0, V3> 0, c(3)))), c(3)))) / 230
v4 <- sum(as.matrix(subset(myakari3d0, V3> 0, c(3)))) / (256 * 256 * 230)
# v5 <- # 欄外に記載
# v6 <- # 欄外に記載 | 「高さを無視する場合」でいこう
でもあなたにはなかまに
できるひとがひとりもいなくてよ
のセリフも用意しておいたから
感謝してよね | v7 <- dist(rbind(mykmakari3dumicenter[ ,c(1,2)], c(127.5, -127.5)))[1 ] / (127.5 * sqrt(2))
v8 <- dist(rbind(mykmakari3dyamacenter[ ,c(1,2)], c(127.5, -127.5)))[1 ] / (127.5 * sqrt(2))
v9 <- dist(rbind(mykmakari3dumicenter[ ,c(1,2)], mykmakari3dyamacenter[ ,c(1,2)]))[1 ] / (255 * sqrt(2))
# 点群がないときはエラー
if (nrow(myakari3dumi)< 2) {
v7 <- c(1)
v9 <- c(1)
}
if (nrow(myakari3dyama)< 2) {
v8 <- c(1)
v9 <- c(1)
}
# 値を置き換える | | しゃきーん★ | myindex9akari <- data.frame(V1=v1, V2=v2, V3=v3, V4=v4, V5=v5, V6=v6, V7=v7, V8=v8, V9=v9) | RからExcelに
値だけをコピーする | write.table(myindex9akari, file="clipboard", col.names=F, row.names=F, sep="\t") |
「さいしょのむら」みたいな村の某「酒場」のひとみたいなひとがなんでも説明してくれる。じゃけんにしないでぜんぶ聞いておくといいことあるかもよ?(違)▼「長久手市にお住まいのラジオネーム「ちょうきゅうめい」さんと電話がつながっています。」については[3707]、それに▼「長久手市にお住まいのラジオネーム「ちょうきゅうめい」さんから『手紙を拾った!』というおたよりが届いていますのでさっそくご紹介しましょう。」については[3722]を参照。
・v5とv6については以下を実行
v5 <- nrow(subset(myakari3d0,( (V3 == 0) & ((V1 == 0) | (V2 == 0) | (V1 == 255) | (V2 == -255)) ))) / 1020
v6 <- nrow(subset(myakari3d0,( (V3 < -3) & ((V1 == 0) | (V2 == 0) | (V1 == 255) | (V2 == -255)) ))) / 1020
※subset関数で使う論理演算子もたいがいだけれど、そもそもこのフォーラムがいけないんです。わるぎはなかった。(※音声を変えています。)
「なんでアニメ限定なの?」のフレーズで「なんでコピペ決定なの?」と不満げに問い返します。どんなコピペが好き?(以下略)ありがとうございました。
> > myindex9akari <- data.frame(V1=v1, V2=v2, V3=v3, V4=v4, V5=v5, V6=v6, V7=v7, V8=v8, V9=v9)
> > myindex9akari
> V1 V2 V3 V4 V5 V6 V7 V8 V9
> 1 0.06897442 0.4138489 0.4299517 0.01478709 0.4970588 0.4294118 0.1826197 0.2381459 0.1984236
これでrbindするなりクリップボードにコピーして『エクセル野帳!』に貼り付けるなりなんでもござれ。
「実行編」([3883])に続きます。
| |